Navigation auf uzh.ch
Navigation auf uzh.ch
To apply, please send your CV, your Ms and Bs transcripts by email to all the contacts indicated below the project description. Do not apply on SiROP . Since Prof. Davide Scaramuzza is affiliated with ETH, there is no organizational overhead for ETH students. Custom projects are occasionally available. If you would like to do a project with us but could not find an advertized project that suits you, please contact Prof. Davide Scaramuzza directly to ask for a tailored project (sdavide at ifi.uzh.ch).
Upon successful completion of a project in our lab, students may also have the opportunity to get an internship at one of our numerous industrial and academic partners worldwide (e.g., NASA/JPL, University of Pennsylvania, UCLA, MIT, Stanford, ...).

Recent research has demonstrated significant success in integrating foundational models with robotic systems. In this project, we aim to investigate how these foundational models can enhance the vision-based navigation of UAVs. The drone will utilize learned semantic relationships from extensive world-scale data to actively explore and navigate through unfamiliar environments. While previous research primarily focused on ground-based robots, our project seeks to explore the potential of integrating foundational models with aerial robots to enhance agility and flexibility.

In this project, we are going to develop a vision-based reinforcement learning policy for drone navigation in dynamic environments. The policy should adapt to two potentially conflicting navigation objectives: maximizing the visibility of a visual object as a perceptual constraint and obstacle avoidance to ensure safe flight.

Use Inverse Reinforcement Learning (IRL) to learn reward functions from previous expert drone demonstrations.

Explore online fine-tuning in the real world of sub-optimal policies.

Reinforcement learning (RL) models devoid of explicit models have showcased remarkable superiority over classical planning and control strategies. This advantage is attributed to their advanced exploration capabilities, enabling them to efficiently discover new optimal trajectories. Leveraging RL, our aim is to create an autonomous racing system capable of swiftly learning optimal racing strategies and navigating tracks more effectively (faster) than traditional methods and human drivers.

Event-based Reinforcement Learning Controller for Drone Racing

Gaussian Splatting meets Reinforcement Learning for Drone Racing

Design and implement efficient event-based networks to achieve low latency inference.

This project aims to develop a sophisticated Reinforcement Learning (RL) environment to train autonomous drones for efficient disaster response operations. By leveraging insights from drone racing research, the project will focus on creating a highly realistic 3D simulation environment.

Develop a vision-based aerial transportation system with reinforcement / imitation learning.

Low Latency Occlusion-aware Object Tracking

Autonomous nano-sized drones hold great potential for robotic applications, such as inspection in confined and cluttered environments. However, their small form factor imposes strict limitations on onboard computational power, memory, and sensor capabilities, posing significant challenges in achieving autonomous functionalities, such as robust and accurate state estimation. State-of-the-art (SoA) Visual Odometry (VO) algorithms leverage the fusion of traditional frame-based camera images with event-based data streams to achieve robust motion estimation. However, existing SoA VO models are still too compute/memory intensive to be integrated on the low-power processors of nano-drones. This thesis aims to optimize SoA deep learning-based VO algorithms and enable efficient execution on MicroController Units.

Autonomous nano-sized drones, with palm-sized form factor, are particularly well-suited for exploration in confined and cluttered environments. A pivotal requirement for exploration is visual-based perception and navigation. However, vision-based systems can fail in challenging conditions such as darkness, extreme brightness, fog, dust, or when facing transparent materials. In contrast, ultrasonic sensors provide reliable collision detection in these scenarios, making them a valuable complementary sensing modality. This project aims to develop a robust deep learning–based navigation system that fuses data from an ultrasonic sensor and a traditional frame-based camera to enhance obstacle avoidance capabilities.

Autonomous nano-drones, i.e., as big as the palm of your hand, are increasingly getting attention: their tiny form factor can be a game-changer in many applications that are out of reach for larger drones, for example inspection of collapsed buildings, or assistance in natural disaster areas. To operate effectively in such time-sensitive situations, these tiny drones must achieve agile flight capabilities. While micro-drones (approximately 50 cm in diameter) have already demonstrated impressive agility, nano-drones still lag behind. This project aims to improve the agility of nano-drones by developing a deep learning–based approach for high-speed obstacle avoidance using only onboard resources.

When drones are operated in industrial environments, they are often flown in close proximity to large structures, such as bridges, buildings or ballast tanks. In those applications, the interactions of the induced flow produced by the drone’s propellers with the surrounding structures are significant and pose challenges to the stability and control of the vehicle. A common methodology to measure the airflow is particle image velocimetry (PIV). Here, smoke and small particles suspended in the surrounding air are tracked to estimate the flow field. In this project, we aim to leverage the high temporal resolution of event cameras to perform smoke-PIV, overcoming the main limitation of frame-based cameras in PIV setups. Applicants should have a strong background in machine learning and programming with Python/C++. Experience in fluid mechanics is beneficial but not a hard requirement.
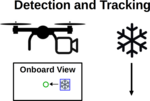
Drones are highly agile and thus ideally suited to track falling objects over longer distances. In this project, we want to explore vision-based tracking of slowly falling objects such as leaves or snowflakes. The drone should detect the object in the view of the onboard camera and issue control commands such that the object remains in the center of the field of view. The problem is challenging from a control point of view, as a drone can not accelerate downwards and thus has minimal control authority. At the same time, the perception pipeline must cope with tracking an object that can arbitrarily rotate during the fall.

Automatic failure detection is an essential topic for aerial robots as small failures can already lead to catastrophic crashes. Classical methods in fault detection typically use a system model as a reference and check that the observed system dynamics are within a certain error margin. In this project, we want to explore sequence modeling as an alternative approach that feeds all available sensor data into a neural network. The network will be pre-trained on simulation data and finetuned on real-world flight data. Such a machine learning-based approach has significant potential because neural networks are very good at picking up patterns in the data that are hidden/invisible to hand-crafted detection algorithms.

The goal of this project is to develop a shared embedding space for events and frames, enabling the training of a motor policy on simulated frames and deployment on real-world event data.

In this project, the student applies concepts from current advances in image generation to create artificial events from standard frames. Multiple state-of-the-art deep learning methods will be explored in the scope of this project.
This project focuses on enhancing SLAM (Simultaneous Localization and Mapping) in operating rooms using event cameras, which outperform traditional cameras in dynamic range, motion blur, and temporal resolution. By leveraging these capabilities, the project aims to develop a robust, real-time SLAM system tailored for surgical environments, addressing challenges like high-intensity lighting and head movement-induced motion blur.

This project focuses on developing robust reinforcement learning controllers for agile drone navigation using adaptive curricula. Commonly, these controllers are trained with a static, pre-defined curriculum. The goal is to develop a dynamic, adaptive curriculum that evolves online based on the agents' performance to increase the robustness of the controllers.

Perform knowledge distillation from Transformers to more energy-efficient neural network architectures for Event-based Vision.

Study the application of Long Sequence Modeling techniques within Reinforcement Learning (RL) to improve autonomous drone racing capabilities.
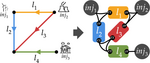
This project explores a novel approach to graph embeddings using electrical flow computations.
This project explores and extends the novel "deep state-space models" framework by leveraging their transfer function representations.

Traditional facial motion capture systems, including marker-based methods and multi-camera rigs, often struggle to capture fine details such as micro-expressions and subtle wrinkles. While learning-based techniques using monocular RGB images have improved tracking fidelity, their temporal resolution remains limited by conventional camera frame rates. Event-based cameras present a compelling solution, offering superior temporal resolution without the cost and complexity of high-speed RGB cameras. This project explores the potential of event-based cameras to enhance facial motion tracking, enabling the precise capture of subtle facial dynamics over time.

In this project, you will investigate the use of event-based cameras for vision-based landing on celestial bodies such as Mars or the Moon.

Explore the use of large vision language models to control a drone.

This research project aims to develop and evaluate a meta model-based reinforcement learning (RL) framework for addressing variable dynamics in flight control.
![]()
We aim to learn vision-based policies in the real world using state-of-the-art model-based reinforcement learning.
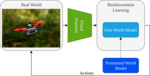
This project aims to use vision-based world models as a basis for model-based reinforcement learning, aiming to achieve a generalizable approach for drone navigation.

The project aims to create a controller for an interesting and challenging type of quadrotor, where the rotors are connected via flexible joints.
