Navigation auf uzh.ch
Navigation auf uzh.ch

Complementary strengths of model-based and user-based instance selection for data labeling. Left: visualization that explains the decision boundaries (bright colors) of a classifier. Uncertainty-based AL strategies (model-based) will select instances near the decision boundaries. Right: visualization that explains the prediction of a classifier for unlabeled data (colors). Users selecting instances may want to resolve the local class confusion, where an instance is classified "green", within the purple class distribution.
Labeling datasets is a precondition to conduct supervised machine learning. The fundamental idea of data labeling is to transform a data instance from unlabeled to labeled by assigning a label to it, allowing it to be used as training data to build models or testing data to evaluate built models. Manually assigning enough labels to support supervised learning in a large dataset would be expensive and time-consuming, so considerable work has been devoted to accelerating the process by reducing human involvement. The standard approach is to carefully select a small set of data instances to manually label, then propagate these labels to unlabeled instances using semi-supervised learning techniques.
A central research question is: which unlabeled data instance should be selected and labeled next? Good instance selection strategies help improve the quality of built models in an effective way. There are many possible instance selection strategies: for example, concentrating on the densest regions first, or starting by selecting one instance per cluster near its centroid.
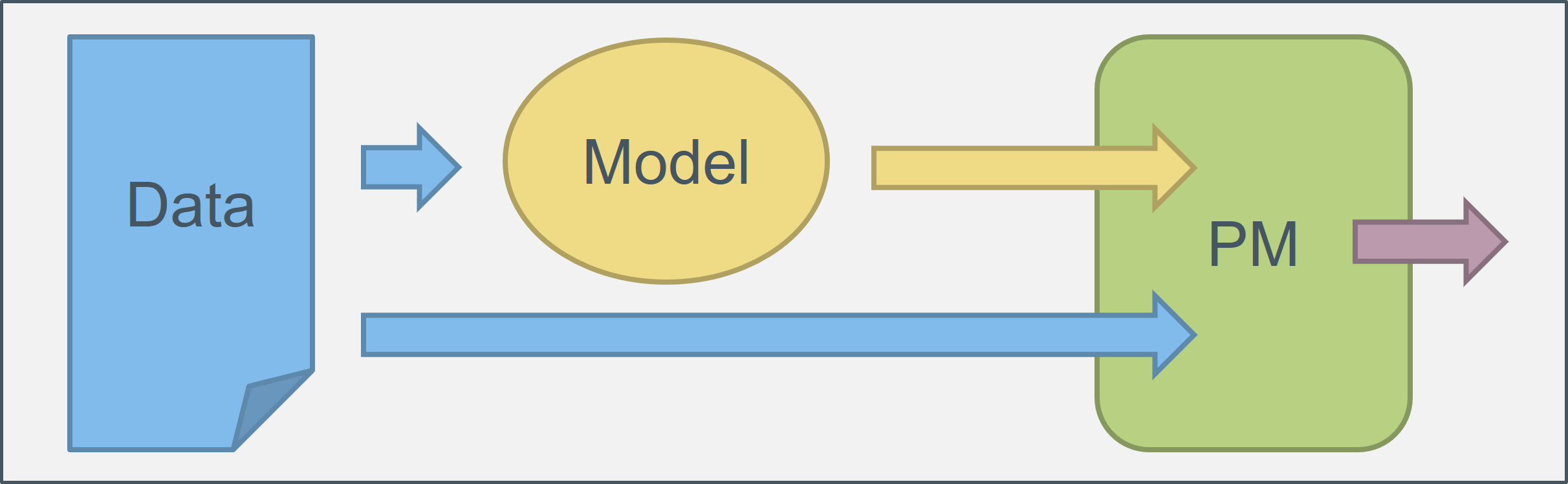
Instance selection strategies have been studied from two perspectives, machine learning (ML) and visual analytics (VA). In this work, we explicitly build upon a unified concept of instance selection, combining both the ML and the VA perspective, referred to as Instance Selection Strategies. The ML-driven perspective is strongly shaped by active learning (AL) instance selection [1], which is a semi-supervised technique where the machine learner proactively asks the user for a label for a specific instance. The VA-driven perspective on instance selection strategies, which we call human-centered (HC) instance selection [2], has been explored by the visualization community. In contrast to the AL, HC approaches employ visual interfaces that enable humans to directly identify and select the next instance to label. Visual interfaces exploit the pattern detection capabilities of human perception, allowing that knowledge to be directly expressed through wise choices of what instance to label next in a way that can immediately be exploited within ML models. While the literature on formalizing HC strategies is minimal to date, HC strategies appear to have complementary strengths to AL strategies [3].In a recent publication, we proposed Property Measures (PM) as a lower-level building block for describing the behavior of instance selection strategies: for each instance (data point) in the input dataset, a PM quantifies a specific property by assigning a numeric output value for it. This concept is very general; concrete examples include Lowest Centroid Distance to assess the centrality property of instances, Largest Median Neighbor Distances to identify outlierness, or Largest Entropy where the probabilistic outputs of a classifier (i.e., class likelihoods) are used to highlight instances of high uncertainty. Virtually any existing selection strategy can be built from combinations of PMs. The explanatory power of PMs comes from considering the full space of possibilities of how they can be constructed and what purposes they can serve.
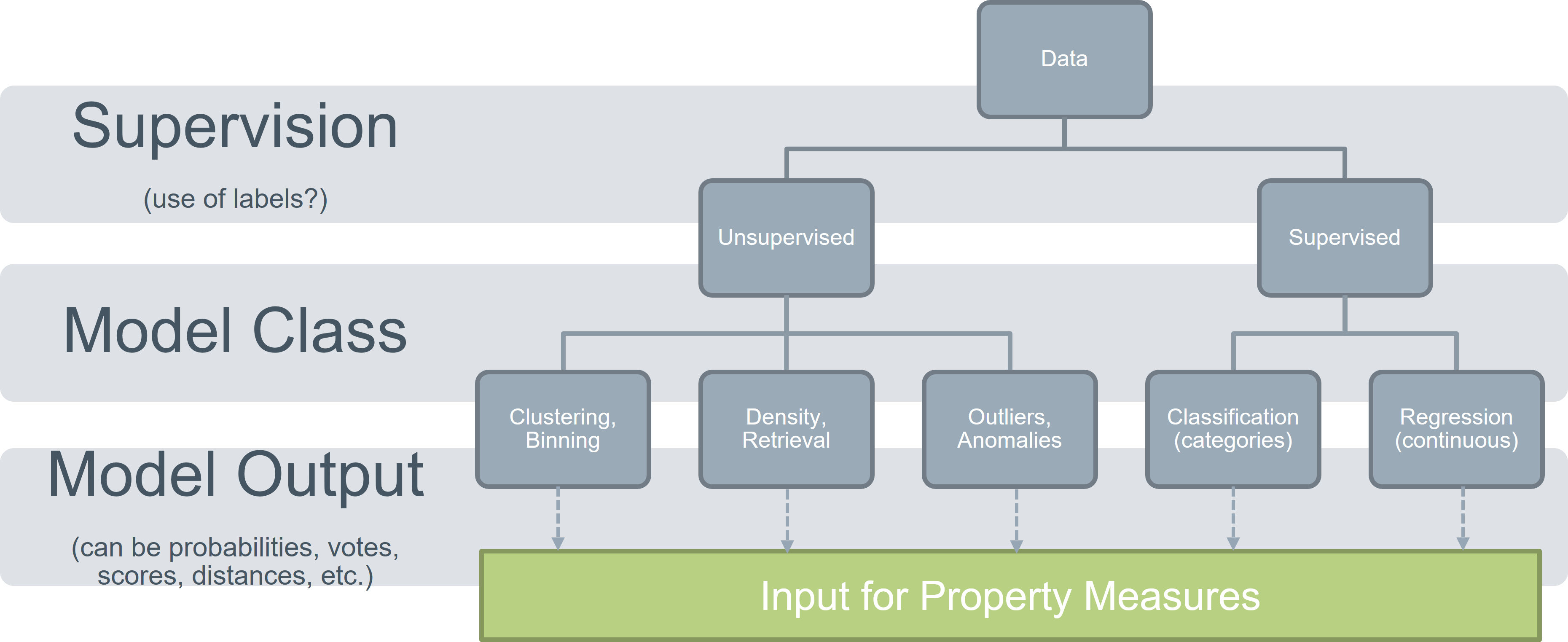
In a recent publication, we have proposed a taxonomy of PMs. This taxonomy eases the design and implementation of PM. The design space covers aspects relevant for instance selection strategies used for active learning, as well as aspects relevant for human-centered instance selection. We have also identified that instance selection strategies in active learning and human-centered instance selection can be characterized by the following 15 properties: Compactness, Centrality, Border, Variation, Separation, Collision, Agreement, Disagreement, Uncertainty, Relevance, Size, Imbalance, Coverage, Outlier, Density.
In this thesis, we will exploit the knowledge about the PM taxonomy and the 15 properties to implement a great variety of PMs. This first goal allows the assessment of various data and model characteristics as used in active learning and human-centered instance selection. The second goal of the thesis is to apply this great variety of PMs to different multivariate datasets. Central analysis questions are about similarities and differences among individual PMs. Informed by these analysis insights, the ultimate goal of the thesis is to compare the great variety of PM implementations with the characteristics of the 15 properties. A driving question is if individual PM implementations match the characteristics of a property? Using the Density property as an example: which PM implementation is most useful to express data density?
Throughout the thesis project several datasets will be used for the analysis. All datasets will be of numerical and multivariate nature, in the notion of feature vectors in many machine learning approaches. The selection of datasets can be based on the student’s suggestions.
To reach the three goals, interactive visual data analysis (IVDA) will be designed along the way. Similarly, as shown in the first figure, scatterplots in combination with dimensionality reduction techniques will serve as a starting point. The backend of the approach will handle data loading, processing, and transformation tasks. In addition, machine learning models such as classifiers and clustering algorithms will be orchestrated. Finally, a framework for PM modeling has to be built.
The written thesis serves two purposes. First, the thesis will document and describe the IVDA tool that has been designed. Second, the thesis is an opportunity for the student to show that the master project has been conducted and written down in a scientific style. As such, the recommended writing language is English, even if not required. The assessment of the written thesis will be based on criteria such as complying to the structure (and the completeness of) scientific manuscripts, the motivation of the approach, the description of the problem statement, the elaboration of related works, the description of the approach (the IVDA tool), the validation effort, as well as a critical reflection on the result of the thesis (plus possible future work).
|
Prof. Dr. Jürgen Bernard The applications should be sent to bernard@ifi.uzh.ch. For questions, feel free to contact Prof. Bernard using this Email as well. |
|
